Now Learning Graph Database, One top product providing parallel processing and scale-out
https://tgcloud.io/app/solutions/create
TigerGraph Cloud Portal
tgcloud.io

https://github.com/tigergraph/gsql-graph-algorithms
GitHub - tigergraph/gsql-graph-algorithms: GSQL Graph Algorithms
GSQL Graph Algorithms. Contribute to tigergraph/gsql-graph-algorithms development by creating an account on GitHub.
github.com
More detailed documentation and examples are available on the web at
https://docs.tigergraph.com/graph-algorithm-library
https://github.com/tigergraph/gsql-graph-algorithms/tree/master/algorithms/examples
< Classfication >
GitHub - tigergraph/gsql-graph-algorithms: GSQL Graph Algorithms
GSQL Graph Algorithms. Contribute to tigergraph/gsql-graph-algorithms development by creating an account on GitHub.
github.com
Certi
https://www.tigergraph.com/certification/
Graph Analytics Course | Graph Database Certification
Receive certifications for designing and implementing graph-based solutions from TigerGraph. Learn more about our graph analytics courses and training now.
www.tigergraph.com
https://www.tigergraph.com/certification/graph-algorithms-for-machine-learning/
Graph Algorithm Machine Learning Certification | TigerGraph
This TigerGraph course examines graph algorithms and how they improve the accuracy of machine learning algorithms. Take the course and earn a certification.
www.tigergraph.com
Overview:
This course examines five different categories of graph algorithms and how they improve the accuracy of machine learning algorithms. In the course, we will examine the following:
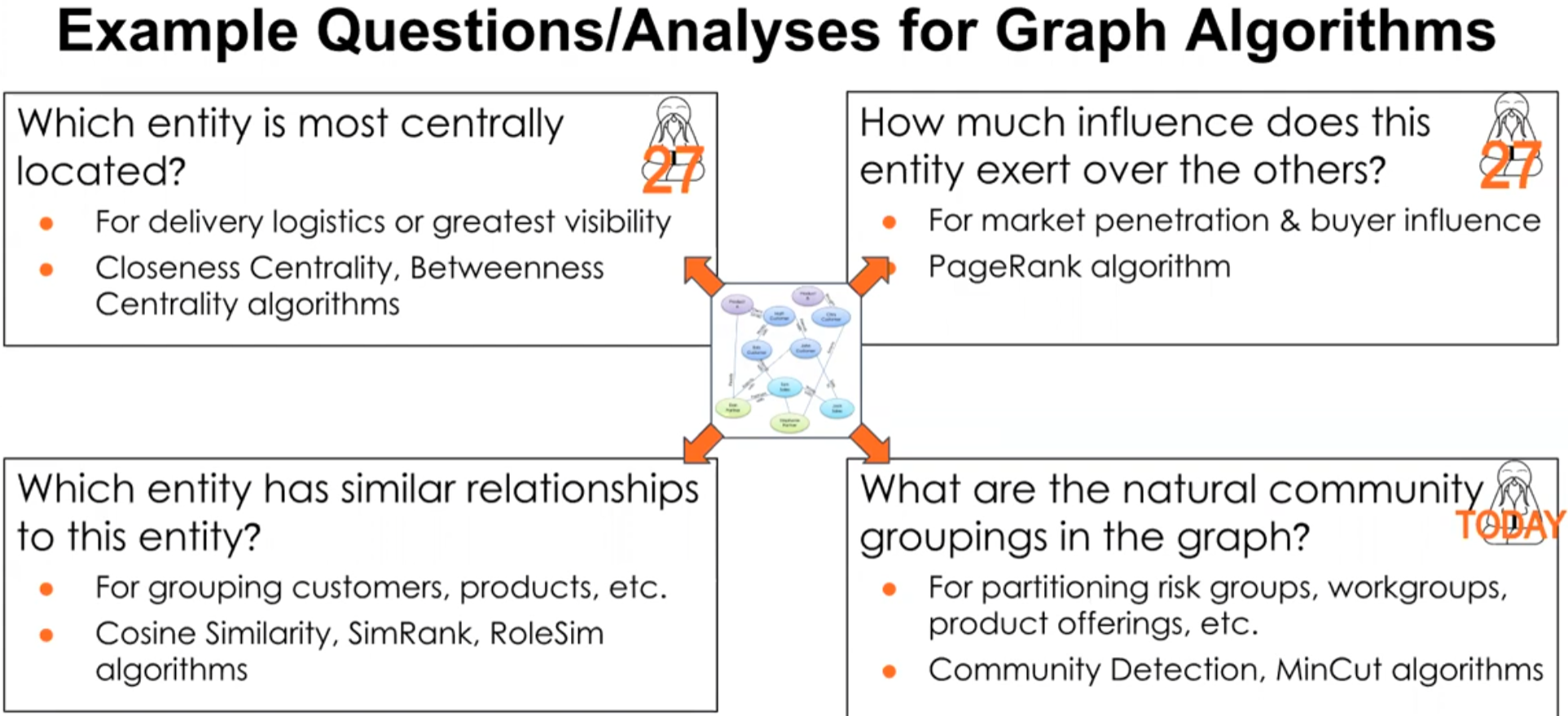
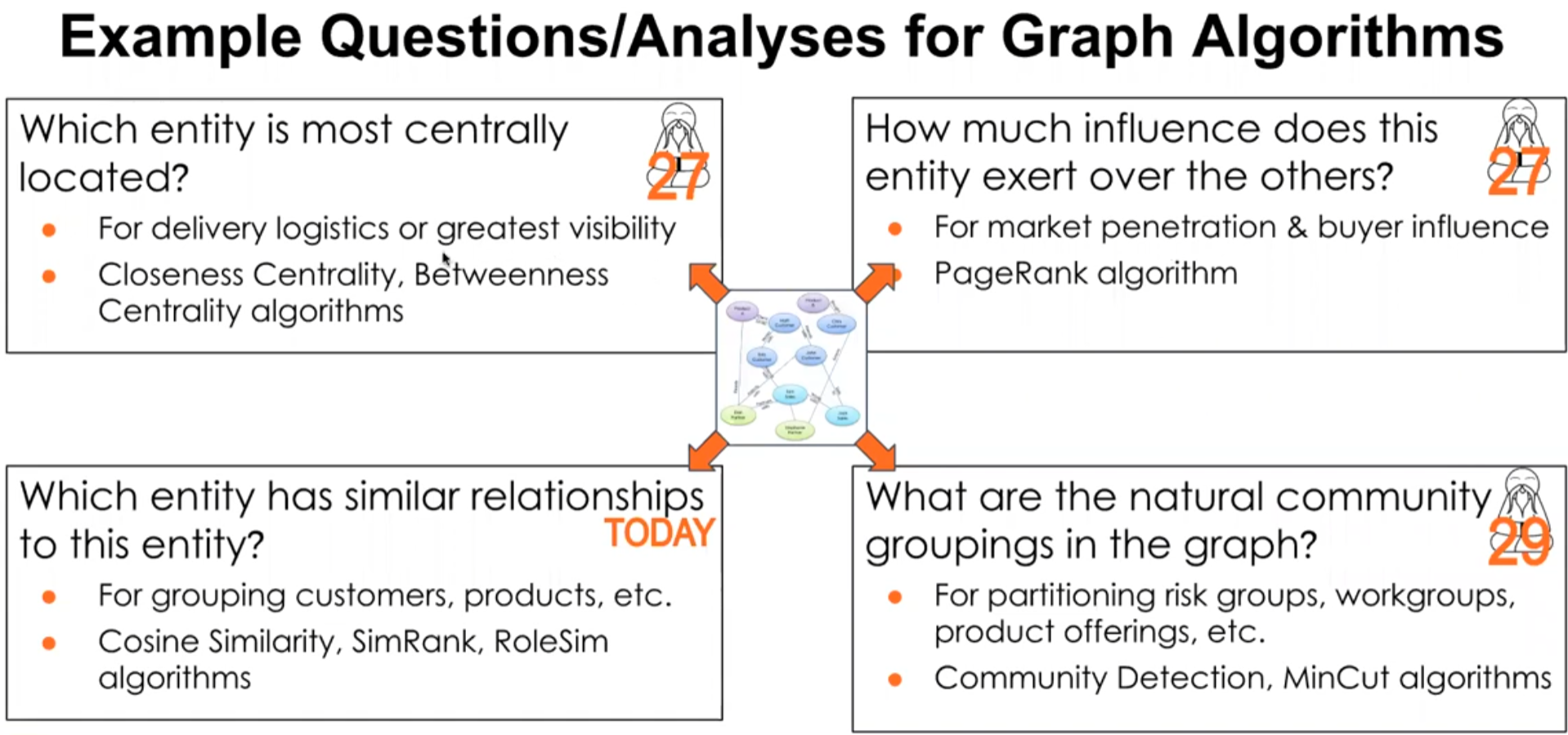
- Shortest path algorithms.
- Centrality algorithms.
- Community detection algorithms.
- Similarity algorithms.
- Classification algorithms.
These graph algorithms can be used for a variety of use cases including entity resolution, fraud detection, knowledge graphs, and recommendation engine.

1st one
분류 추천 추론
Segmentation
Funnel Analysis
Basic Data Exploration


최적화 : 얼마나 짧은 단계를 거쳐서 도달할 수 있는가
영향력 : 누가 가장 중요한 영향력을 가지고 있는가
유사도 : 무엇을 기준으로 유사하다고 할 수 있는가 관계의 구조도, 순서가 고려된, 패턴
Classification : 분류
K nearest neighbourhood : What is proper starting K
K means clustering
PageRank : Probability Distribution


Search
TigerGraph(Parallel Processing) : Breadth-first search (Advantage of parallelism) / Depth-first search (Sequetial- one by one)
Path Findings
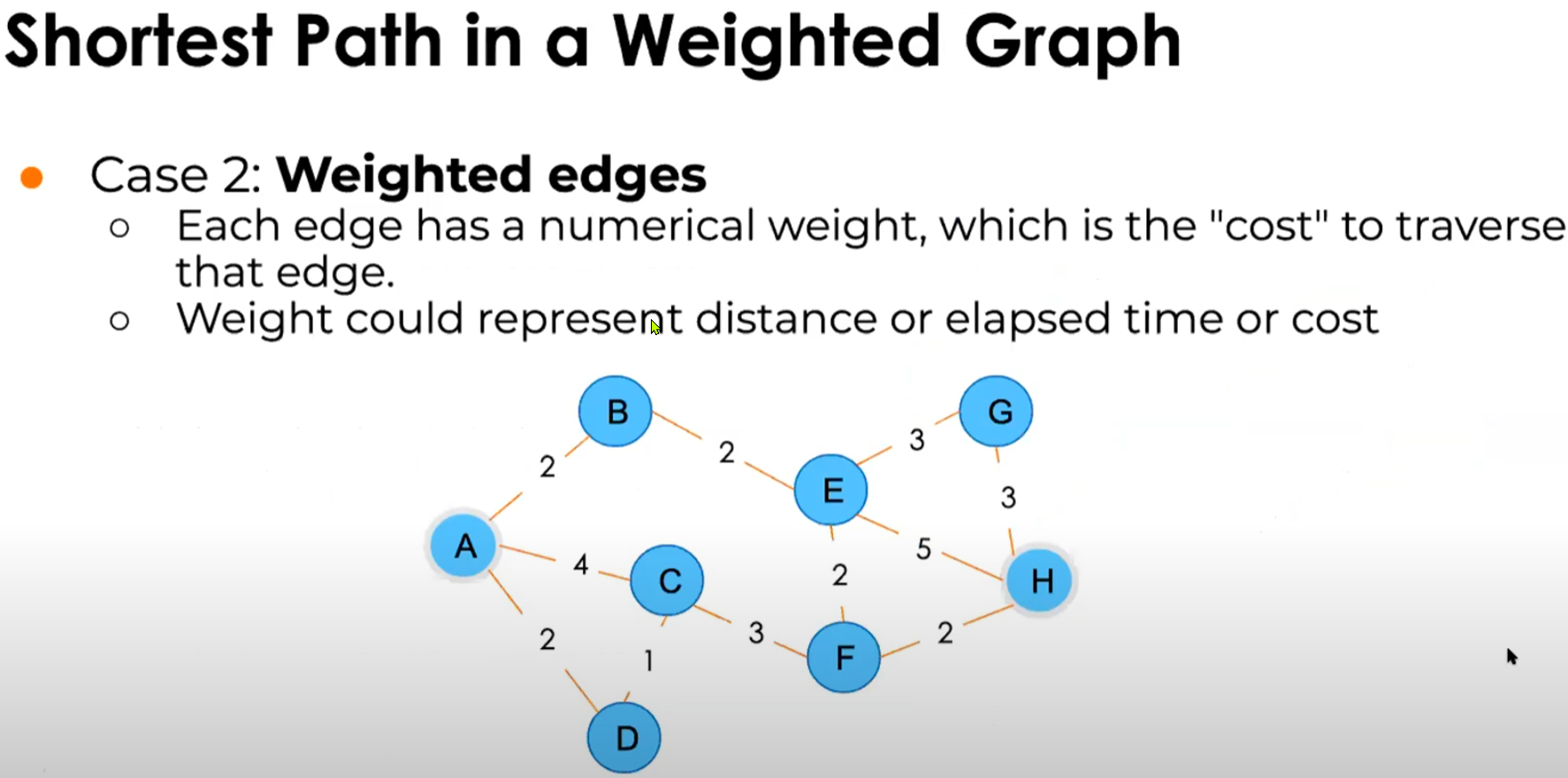
Is there a path from A to H ?
What is the shortest of cheapest path ?
What is the degree of separation (number of hops) ?
The smaller the degree, the greater the knowledge/influence/trust of the other
Likelihood of encountering one aonther
Referral for jobs, etc.




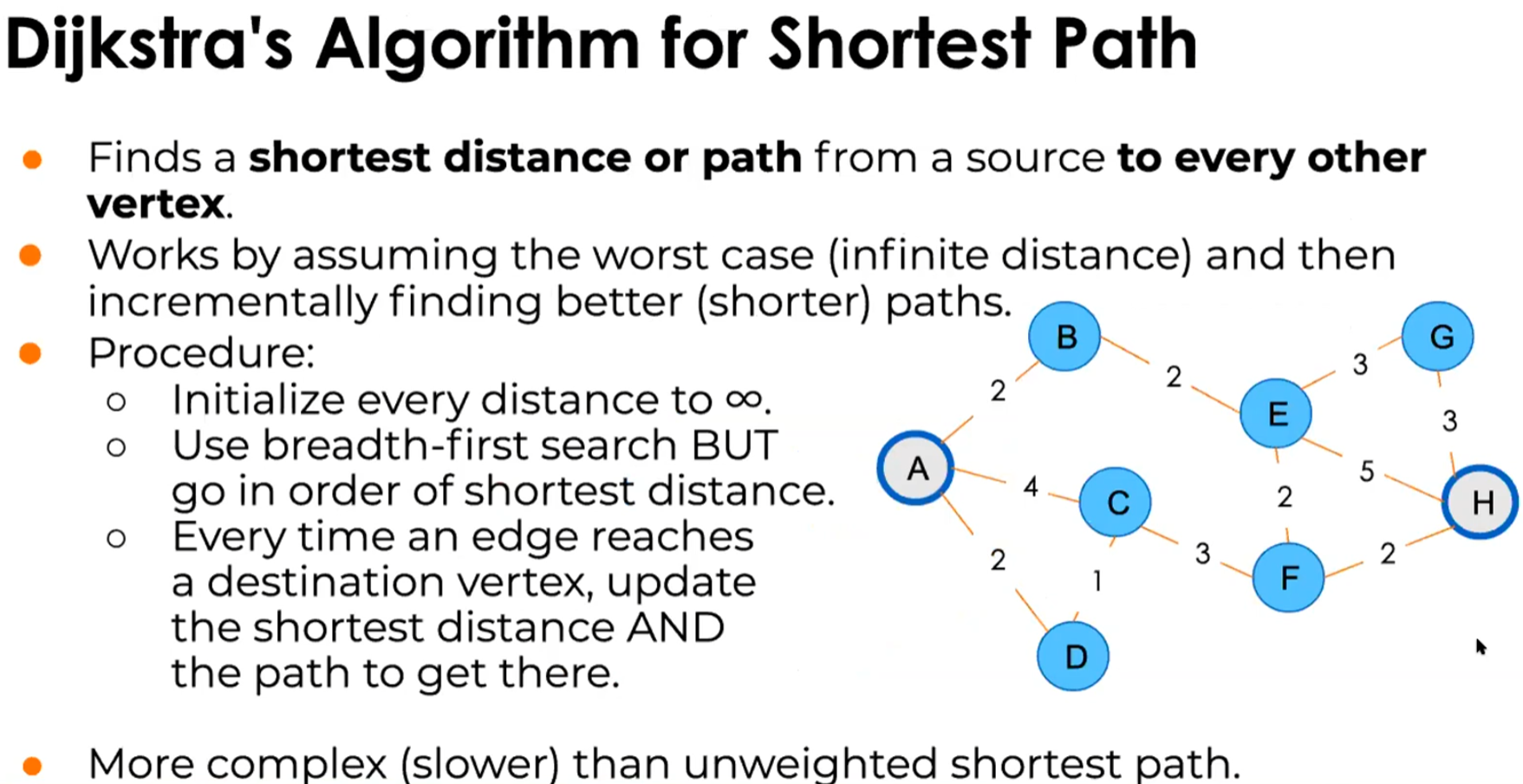
<Dijkstra's Algorithm for Shortest Path>
Works by assuming the worst case (infinite distance) and then incrementally finding better(shorter) paths
Procedure
Initialize every distance to 무한대 ee infinite
Use breadth-first search But go in order of shortest distane
Every tie an edge reaches a destination vertex, update the shortest distance AND the path to get there

Dijkstra's may be characterized as a greedy algorithm, which builds the shortest-paths tree one edge at a time, adding vertices in non-decreasing order of their distance from the source. That is, in each step of the algorithm, we will find the next-closest vertex to the source. (If there is a tie, it does not matter which one is chosen.) We assume below that all nodes are reachable from the source. (If you find the two sections below too difficult, skip them.)
source : https://wcipeg.com/wiki/Dijkstra%27s_algorithm
데이크스트라 알고리즘 - 위키백과, 우리 모두의 백과사전
컴퓨터 과학에서, 데이크스트라 알고리즘(영어: Dijkstra algorithm) 또는 다익스트라 알고리즘은 도로 교통망 같은 곳에서 나타날 수 있는 그래프에서 꼭짓점 간의 최단 경로를 찾는 알고리즘이다.
ko.wikipedia.org
- Dijkstra 알고리즘의 핵심은 시작점 k 부터 u까지 도달하는기 위해서는 k에서 가장 가까운 경로부터 탐색해야 한다는 점이다. 그러니깐, k로부터 가장 가까운 지점을 계속 탐색하는 것이다.
알고리즘 : 컴퓨터에게 인간한 생각하고 시도하려는 방식을 ,01010101 형태를 가지고 계산하는 컴퓨터에게 일을 시키는 방식이다 고 혼자 생각해본다 끄적거림
https://blog.naver.com/newtechlead/222385164524
[그래프 최단경로 알고리즘] Dijkstra 다익스트라
플로이드-와샬 알고리즘이 있지만 이 알고리즘은 구현은 쉽지만 O(N3)의, 상당히 비효율적인 시간복잡도...
blog.naver.com
source : 위 블로그 페이지 (공부를 위해 일부 캡쳐함)


Who knows whojm ?

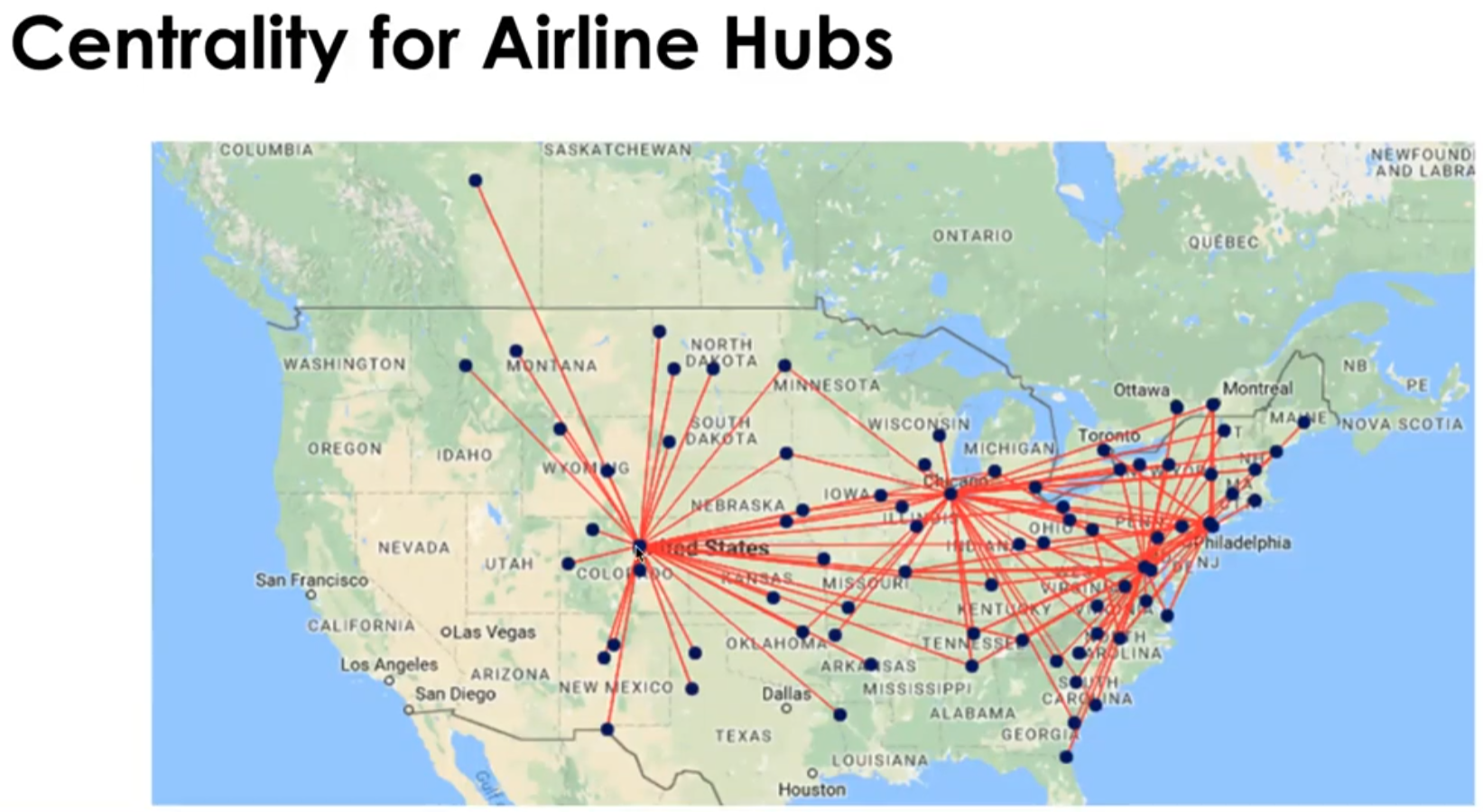


< Closeness Centrality >
Compute average distance from a vertext to every other vertex

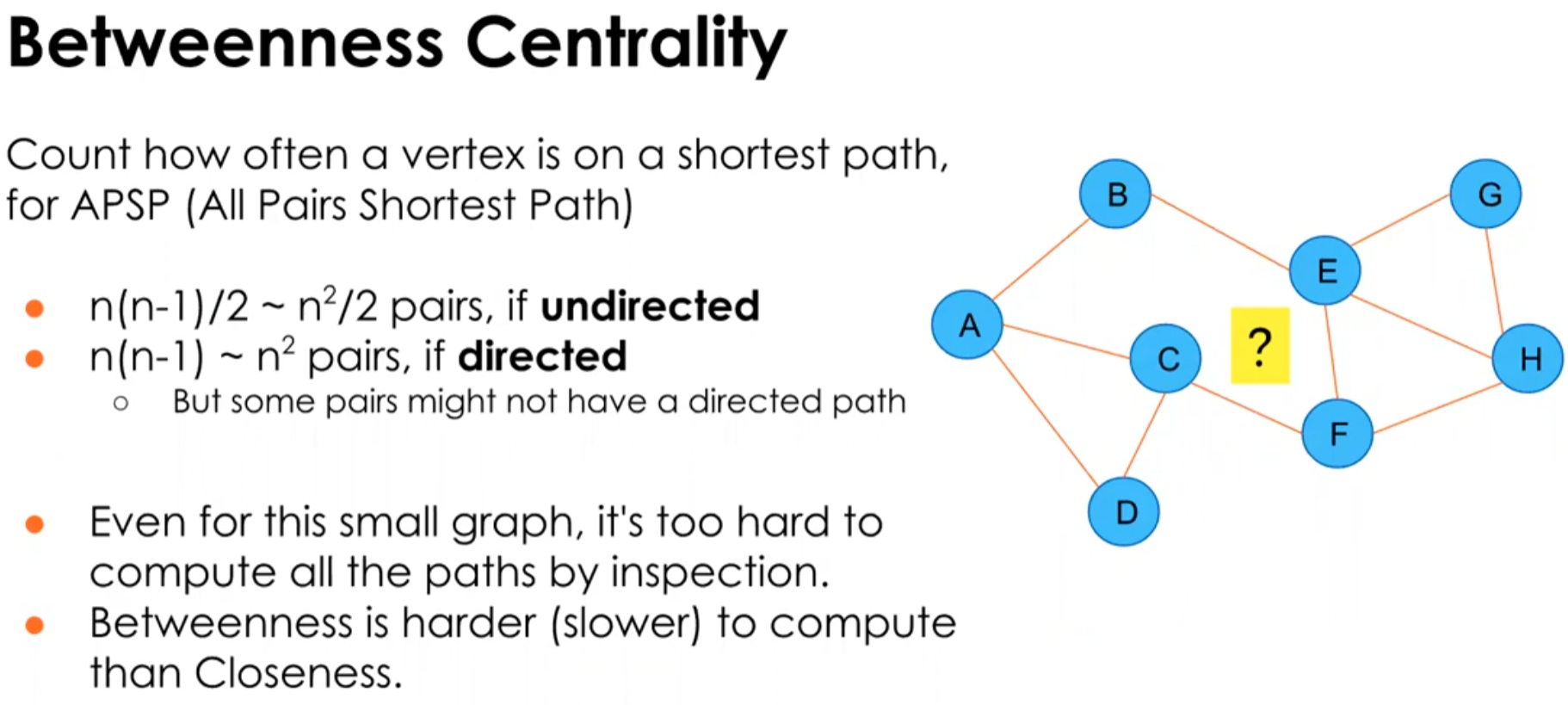
<Betweenness Centrality>
가장 짧은 지름길들이 가장 자주 거쳐가는 Vertex
Betweenness is harder (slower) to compute than Closeness ( 계산량이 더 많다, 모든 path 를 계산해서 비교해 주어야 한다. 연산량이 더 많다)
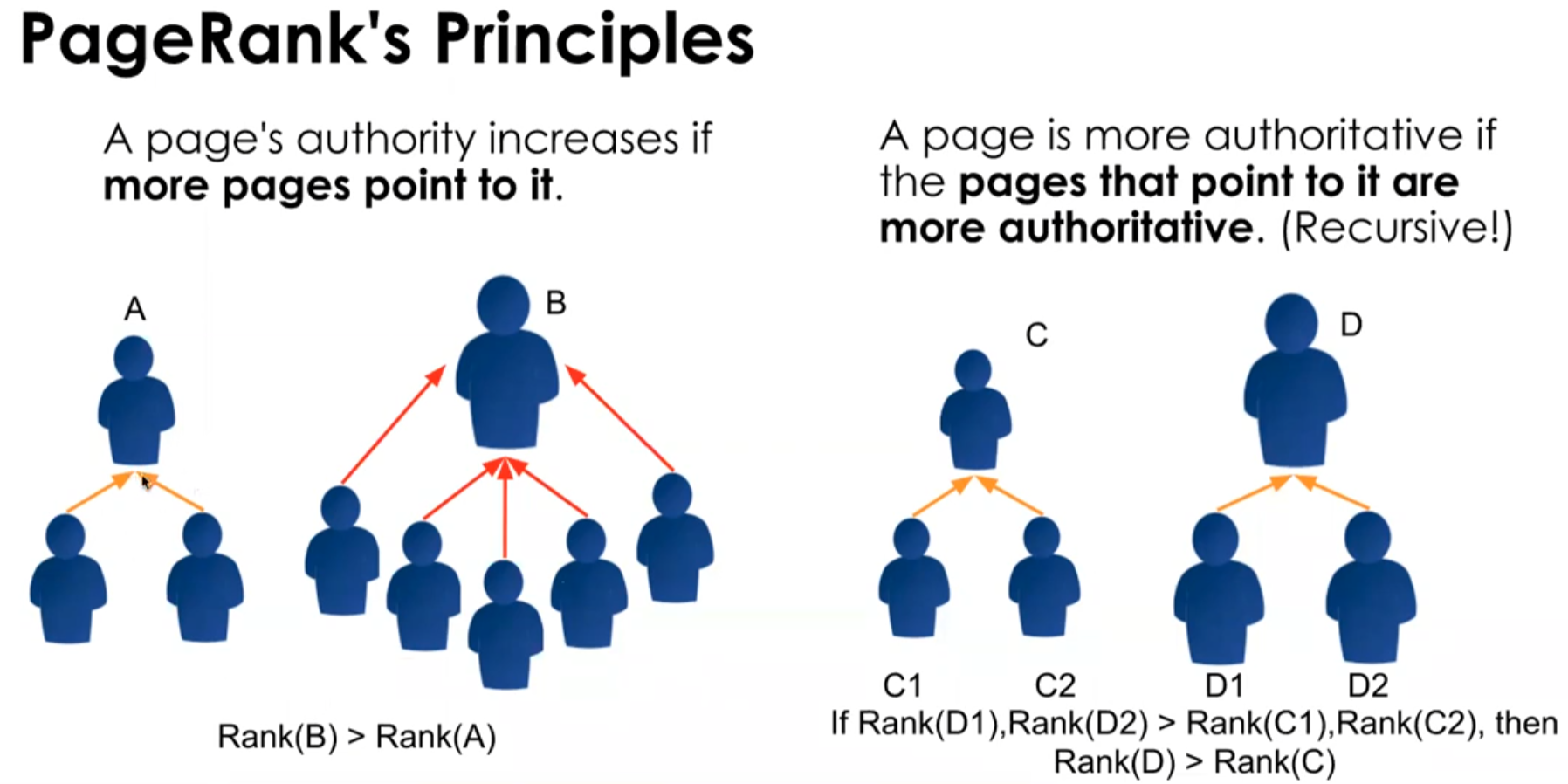
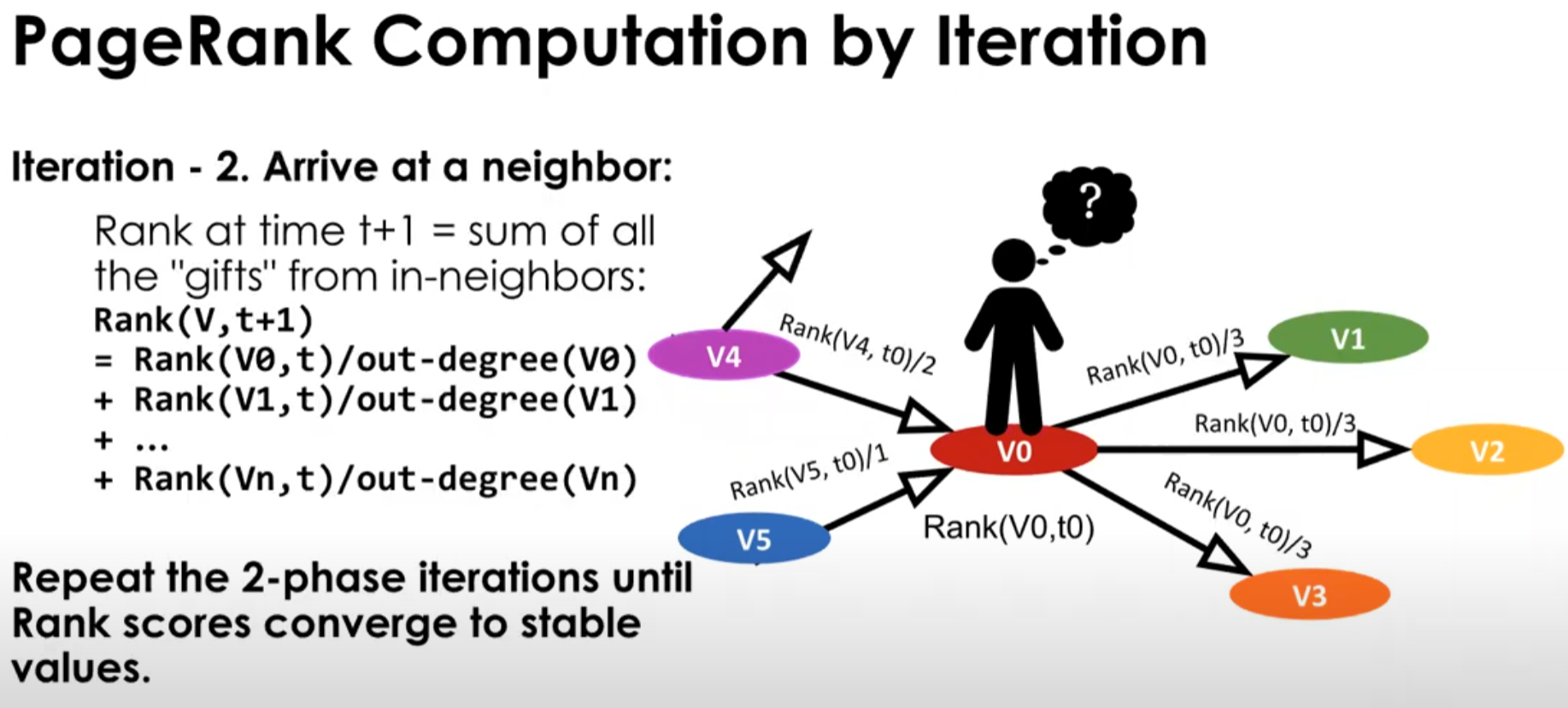
<PageRank>
Find the most "authoritative" page in the web. The page is authoritative because it is frequently referred by the web pages having many visitors.





Demo

Centrality
Betweeness
Closeness Centrality
Closeness (Inverse of distance)
Eigen Vector
RDB
Covered Index
Data Skewness
Multi Segment Leg
Simple Centrality
Select count(*), sum(edge_strenth) from table100
group by source, target
order by count(*) desc
limit 10
Select count(*), sum(edge_strenth) from table100
group by source, target
order by sum(edge_strenth) desc
limit 10
GSQL
Data Analyst Perspective
Engineering Perspective
< Community Detection >






K Means Clustering
K Nearest Neighbourhood
Supervised Learning vs Unsupervised Learning
Ummm... Partitioning (Rule-based ? )



<Louvain Modularity>
How good is the partitioning of a graph

https://mons1220.tistory.com/129
[네트워크이론] Louvain algorithm for community detection
network로부터 community를 추출하는 방법으로 Girvan-Newman algorithm와 Link community를 소개한 적이 있었다. 오늘은 그 3탄으로 Louvain algorithm을 소개하려고 한다. Louvain algorithm이 처음 소개된..
mons1220.tistory.com
첫 phase에서는 한 node를 원래의 community에서 빼어내어 인접한 community에 재배치 하였을 때의 modularity의 변화를 측정한다. 측정값을 기준으로, modularity가 가장 큰 폭으로 상승하는 community에 node를 배속 시킨다. 어떤 변화도 일어나지 않을 때 까지 수행한다.
이 방법은 한개의 node 1번 부터 100번 까지의 node가 있다면, 이 작업을 어떤 노드부터 수행하는가에 따라 다른 결론이 도출될 수 있는데, 저자들은 여러번의 실험결과 이러한 순서가 도출되는 modularity에 큰 영향을 끼치지 않는다는 것을 알아냈다. 하지만, 바뀐 순서는 계산 속도에 영향을 줄 수 있다는 것도 알아냈는데, 추후 순서를 어떻게 정할지 추가적으로 연구할 필요가 있다고 한다. (2008년 논문이므로 이미 나와있을 수도..)
첫 phase에서는 modularity 변화량을 다음과 같이 정의한다.
modularity 변화량 = node i가 community에 배속된 상태의 modularity - node i가 배속되지 않은 상태의 modularity

m : 모든 link weight의 합




<Similiarity>
Tech Engineering 관점의 성능
Performance of Algorithm
Performance of Database products w/ large dataset (Parallel Processing)
https://towardsdatascience.com/10-graph-algorithms-visually-explained-e57faa1336f3
10 Graph Algorithms Visually Explained
A quick introduction to 10 basic graph algorithms with examples and visualisations
towardsdatascience.com
https://skilllx.com/foundations-of-recommendation-system/
Foundations of Recommendation System - Skilllx
Recommendation systems are one of the most visible examples of machine learning such as Amazon recommendation system, Facebook recommendation system.
skilllx.com
What is Jaccard Similarity?
The Jaccard index, also known as Intersection over Union and the Jaccard similarity coefficient, is a statistic or measure used for gauging the similarity and diversity of sets.
Jaccard(A,B)= ∣A⋂B∣ / ∣A∪B∣
which shows 100% match. Maximum value of jaccard is 1 (full match) and minimum is 0 (mis-match).Note: Jaccard Similarity cannot consider order of elements which is problematic as shown in above example.
What is Cosine Similarity?
Consider following vectors, where there two sentences “this is book” and “this is book and i have read it thrice”, these two sentence are similar but due to the length difference, it will calculated less similar by Jaccard and Euclidean formula.
If we focus on angle between two vectors, we might get good result. In above figure, length difference of two vectors is large but the angle is less. We can calculate angle between vectors:-
The angle between two sentences is 55^0
Note: Calculator must be in radian mode.
https://blog.naver.com/smmok/222439545464
TEXT 유사도.자카드 유사도(Jaccard Similarity)코사인 유사도(Cosine Similarity) 알아보기
TEXT 유사도. 알고리즘 : 텍스트가 얼마나 유사한지를 표한하는 방식 중 하나 검색 엔진에서 검색어(Q...
blog.naver.com
아래 내용 추천 - 정리가 잘 되어 있음 Cosine and Jaccard // Manhattan and Mahalanobis distance
https://brunch.co.kr/@gimmesilver/39
군집 분석 #2
유사도(similarity)와 거리(distance) 지난 번 글에서 언급했듯이 군집 분석을 하려면 먼저 개체간의 비슷한 정도를 어떻게 정량화할지 정해야 합니다. 이런 비슷한 정도를 '유사도' 혹은 '거리'라고
brunch.co.kr
문서 유사도: 코사인 유사도, 자카드 유사도, 유클리드 거리
문서 유사도란 문서 간에 얼마나 유사성을 갔는지에 대한 지표를 의미한다. 문서 유사도는 자연어처리에서 자주 사용되는 방법으로, 문서 간의 비교 뿐만 아니라 문서 내의 단어들 간의 비교에
daanv.tistory.com
Graph Studio

File Uploading
직관적이지 않음
파일을 끌어다 Drag and Drop 형태로 하려 했으나 이 방식으로 작동 안함

위 버튼을 누르고 무엇을 어떻게 해야 하는지 표현이 안됨
위 버튼을 누르고 '무엇을 선택하라는 메세지' 가 없어서 당황 스러움
업로드할 파일을 선택하시오 또는 Vertex / Edge 를 선택하시오가 나와 주어야 할 것 같음

그 다음 file 과 vertex 의 매핑임

csv 파일의 특정 컬럼 클릭후 Airport 의 특정컬럼을 선택하면 화살표선이 생김 (이것도 직관적이지 않음?)
무언가 깜박이 가 있어야 할듯 (최초에는 친절가이드 모드 그리고 이후 안내를 끌 수 있도록 옵션을 주는 것이 좋을 것 같음 )
더블클릭은 constant 값임



https://www.tigergraph.com/blog/accumulator-101/
Accumulator Variables & Types | Accumulator 101 | TigerGraph
This short tutorial aims to shorten the learning curve of accumulator. Learn more about accumulator types and variables from TigerGraph.
www.tigergraph.com
'Intro Jacob' 카테고리의 다른 글
| Graphdatabase 이해 (0) | 2021.08.29 |
|---|---|
| TigerGraph World II (0) | 2021.07.31 |
| One of the authors of the book [Data Architecture Professional] (0) | 2021.07.14 |
| Jacob Jo - MariaDB (0) | 2021.07.02 |
| 2019 AWS Summit ClustrixDB intro (0) | 2019.04.18 |



